面向服务机器人的视听感知融合与多模态人机交互关键技术
本项目是来源于国家自然科学基金,题名:面向服务机器人的视听感知融合与多模态人机交互关键技术(NO. U1613209), 起止时间2017.01-2020.12。本项目工作简单总结如下:
1. 主要研究成果
本项目针对服务机器人在智能人机交互过程中,由于机器人平台的移动性引入的视觉、听觉、深度感知等感知特征的
连续变化面临的复杂性,研究了视觉听觉感知融合和多模态人机交互关键技术。建立支持多模态人机交互的感知-运动“位姿空间”
统一建模方法,提出基于概率增强策略,基于多模态感知信息与三维动态点云技术对物理空间建模并实时更新,
提出基于感知与运动信息结合的高维位姿空间优先映射策略,来优化从物理空间到高维位姿空间的映射。具体来说,主要研究内容包括以下5个内容:
(1) 面向多模态人机交互的“感知运动位姿空间”统一建模方法
(2) 基于视觉听觉融合的复杂交互场景人体目标定位与跟踪
(3) 基于视听融合的交互对象行为识别与理解
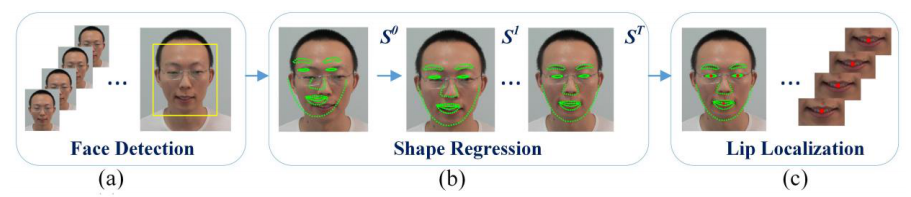
在基于视听融合的唇语识别任务中,为了关注人脸的唇部区域,我们对唇部提出一种新的几何特征描述方法。在基于回归的人脸特征点定位方法中,
首先检测一个粗略的人脸区域,如下图所示:
在表情识别、唇语识别领域,LBP,HOG,和Gabor特征的使用已经屡见不鲜。虽然这些传统的特征提取方法已经取得了一定的成绩,但还存在提升的空间。 因此我们对这些传统的特征描述子引入编码、池化等机制,而非直接使用这些传统特征或者它们的融合来进行外观特征的提取。
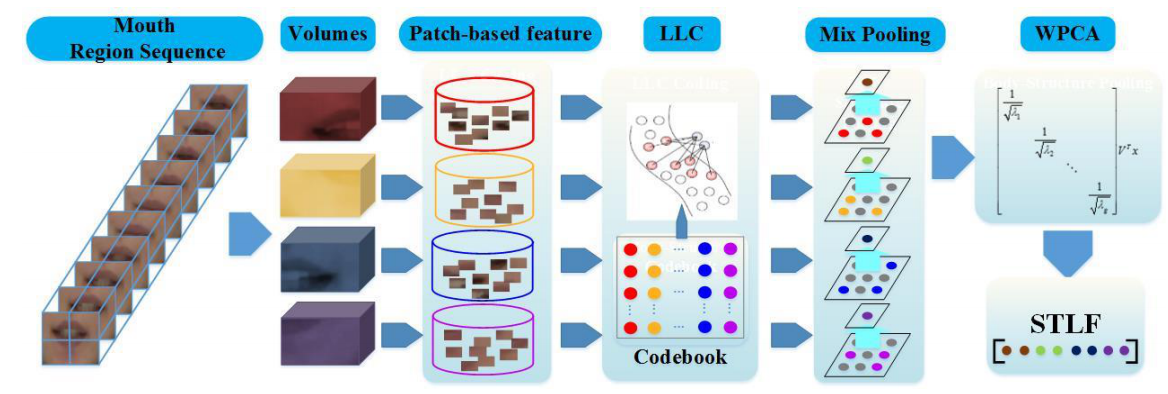
不同的说话人说相同内容的时候,虽然表达相同的语言文字内容,但是由于个人唇部外观的差异,使得同类说话内容在视频图像序列样本中表现出较大的类内差异。为了获取鲁棒的特征,同时缩小类内差距, 我们在基于面部特选区域分割的基础上,提出一个嘴唇时空外观特征(Spatiaal-Temporal Lip Feature, STLF),其过程如下图所示:
在关键词识别验证里,我们提出的双向同步融合的唇部图辅助的音视频关键词检测识别验证方法如下图所示,我们使用一个音频流来从语音信号中提取语音特征, 并用一个混合视觉流来从视觉信号中提取视觉特征。最后一个双向同步融合模块被用来融合语音特征和视觉特征。方法示意图如下图所示:

(4) 基于视听与深度感知融合的交互对象唇部运动检测
(5) 基于视听与深度感知融合的交互对象运动检测
2. 项目取得成果的总体情况
在本项目支持下,课题组成员发表期刊论文10篇,会议论文25篇,专利申请13项,软件著作权两项。
理论成果:
针对基于视听融合的唇语识别任务,本文提出唇部外观时空特征与形状差分特征相结合的方法,
在权威公开唇语识别数据库OuluVS上取得了87.55%的正确率,超越目前主流方法。
针对音视频关键词识别验证任务,本文提出双向同步融合的唇部图辅助的音视频关键词检测识别验证方法,在大型公开数据集LRW上取得了超越基线模型0.39%到6.49%
(基于信噪比从20dB至-5dB)的提升。
实验系统:
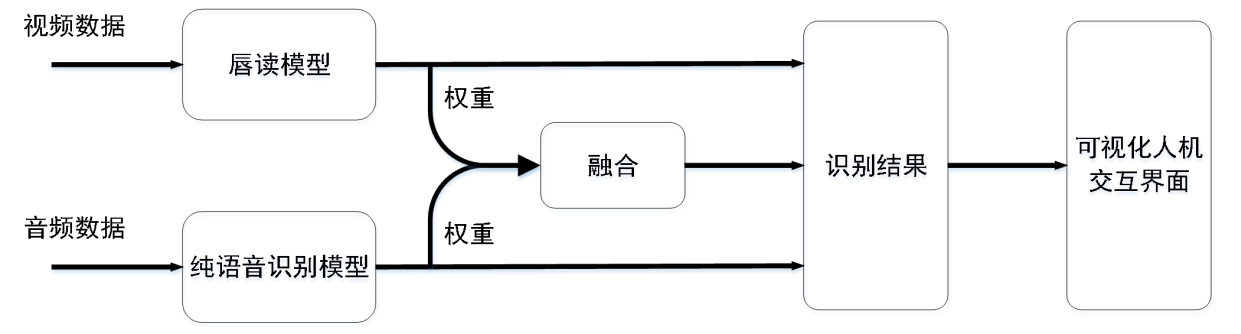
针对音视频语音识别任务,本文设计的音视频语音识别系统框架下图所示。
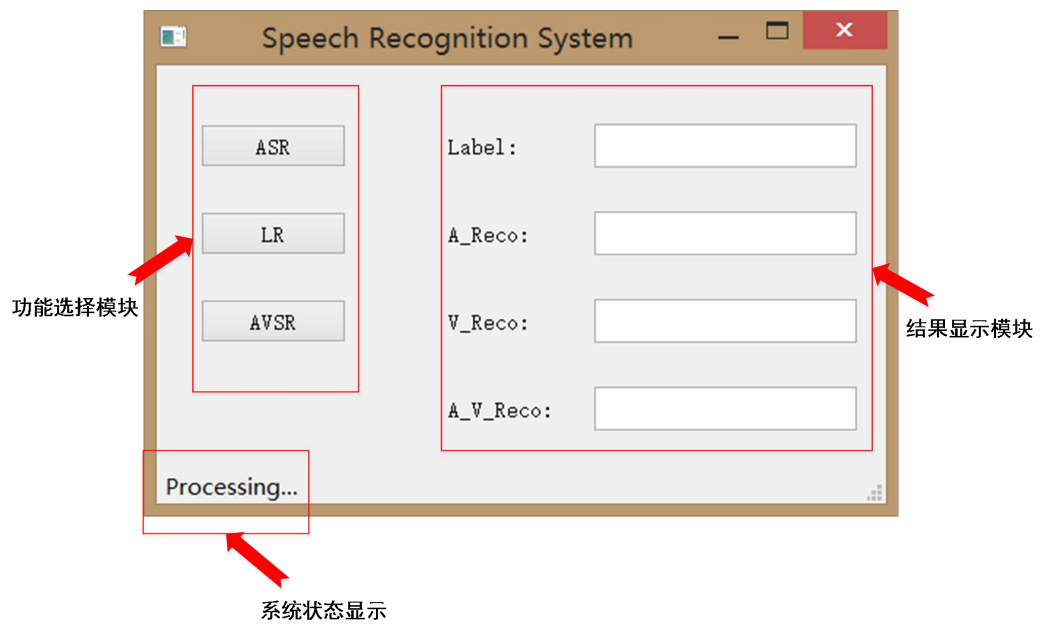
本研究主要用PyQt5的QtCore、QtGui、QtWidgets等三个模块来进行可视化人家交互界面的开发, 系统界面如下图所示,点击“ASR”按钮即可进入纯语音识别模式,点击“LR”按钮即可进入唇读模式,点击“AVSR”按钮即可进入音视频语音识别模式。